Why Traditional Benchmarks Fail RAG Evaluation
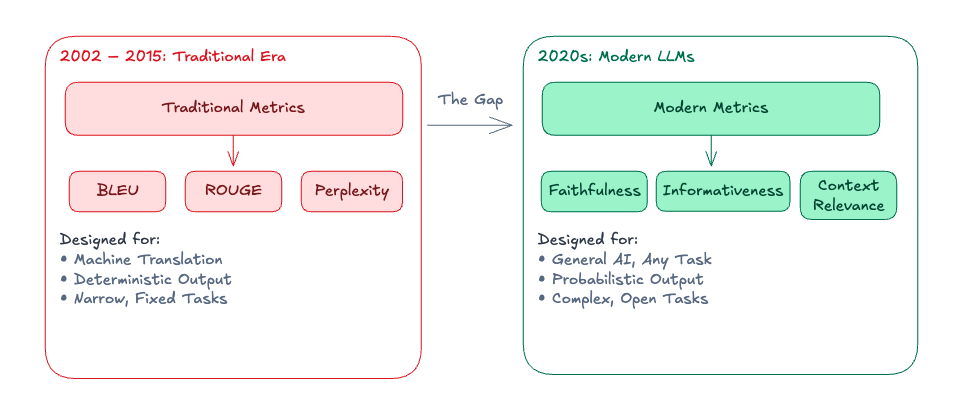
If you work with RAG systems in production, you’ve probably noticed that BLEU and ROUGE scores tell you almost nothing useful. A system can score 0.78 BLEU and still hallucinate financial figures. A system with 0.40 BLEU might be more useful to real users. Traditional metrics were designed for narrow, deterministic tasks — machine translation against reference translations, text summarization against human-written summaries — where the space of valid outputs is small and reference-matching is meaningful.
Modern RAG systems break these assumptions. There’s no single “correct” way to phrase an answer, responses depend on retrieved context that varies per query, and the most important failure mode — confabulation — is invisible to n-gram overlap metrics.
This RAG evaluation guide covers what to measure instead, how the metrics work under the hood, and what breaks in practice when you take these systems to production.
The RAG Evaluation Metric Landscape
Before picking a LLM evaluation framework, it helps to understand the three families of evaluation approaches and their tradeoffs:
Lexical / statistical metrics (BLEU, ROUGE, exact match): Fast, cheap, deterministic. Useful only when you have reference outputs and the task is closed-form. Use for extractive QA, slot-filling, or anywhere a canonical answer exists.
Model-based metrics (BERTScore, MoverScore, NLI-based): Use a pretrained model to compare semantic similarity or check entailment. More expensive but correlation with human judgment is better. NLI-based approaches (checking whether claim B is entailed by premise A) underpin most modern faithfulness metrics.
LLM-as-judge: Use a capable LLM to score responses on dimensions like correctness, helpfulness, or faithfulness. Highest correlation with human judgment for open-ended tasks, but comes with its own bias catalog (more on this below). Most expensive.
For RAG specifically, you typically want a mix: cheap deterministic checks in CI, model-based NLI for faithfulness at scale, and LLM-judge for a sample of production traffic.
RAG-Specific Evaluation Metrics: The Four Dimensions
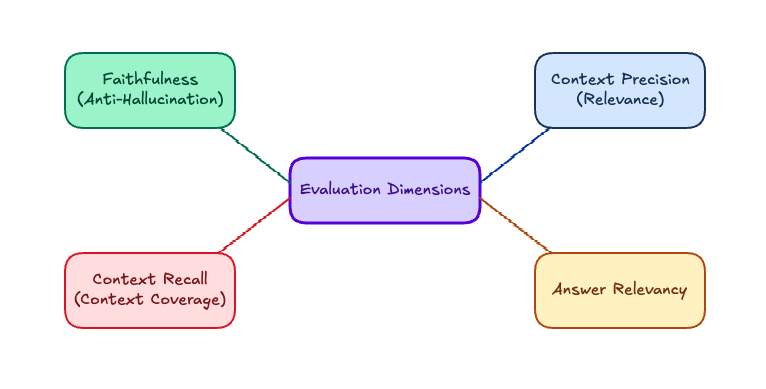
Faithfulness
Faithfulness measures whether every claim in the response is supported by the retrieved context. The standard implementation:
- Claim extraction: decompose the response into atomic propositions. “The study ran for 8 weeks and found 67% improvement” becomes [“The study ran for 8 weeks”, “67% of participants improved”].
- Entailment checking: for each claim, ask an NLI model (or LLM) whether the context logically entails it.
- Score:
supported_claims / total_claims
from ragas.metrics import faithfulness
from ragas import evaluate
from datasets import Dataset
# A case where the model adds information not in context
data = Dataset.from_dict({
"question": ["What were the trial results?"],
"answer": [
# Model said '2 weeks' — the context says '8 weeks'
"The treatment showed 67% improvement within just 2 weeks."
],
"contexts": [[
"The study found that 67% of participants improved after 8 weeks of treatment."
]],
"ground_truth": ["67% of participants improved after 8 weeks."]
})
results = evaluate(data, metrics=[faithfulness])
print(results)
# faithfulness: 0.5 (one claim verified, one hallucinated)
What breaks: Short responses score artificially high because there are fewer claims to verify. A response of “The results were positive” is technically faithful to almost any positive-outcome context. Also, faithfulness only checks whether claims appear in context — it doesn’t check whether the context is itself accurate.
Context Precision and Recall
These two metrics evaluate the retriever, not the generator. They’re easy to conflate but measure opposite things.
Context precision: Of the chunks retrieved, what fraction were actually relevant to answering the question?
context_precision = relevant_retrieved / total_retrieved
Low precision means your retriever is pulling noise. The generator is forced to work with irrelevant context, which increases hallucination risk — especially if the relevant signal is diluted.
Context recall: Of the facts needed to answer the question correctly, what fraction were present in the retrieved chunks?
context_recall = facts_in_retrieved / total_facts_needed
Low recall means the retriever is missing relevant chunks. No matter how good your generator is, it can’t answer from context it never saw.
The practical implication: if you’re debugging a RAG failure, check these two first. A hallucination with high context recall is a generator failure — the answer was there and the model ignored it. A wrong answer with low context recall is a retriever failure — fix the retrieval, not the prompt.
from ragas.metrics import context_precision, context_recall
# Example with a multi-hop question
data = Dataset.from_dict({
"question": ["What was the treatment duration and its effect on the control group?"],
"answer": ["Treatment ran for 8 weeks. The control group showed 12% improvement."],
"contexts": [[
"The study ran for 8 weeks.",
"Treatment group showed 67% improvement.",
# Missing: control group data — this is a recall failure
]],
"ground_truth": [
"The treatment lasted 8 weeks. The control group showed 12% improvement."
]
})
results = evaluate(data, metrics=[context_precision, context_recall])
# context_precision: 0.67 (2 of 3 chunks relevant)
# context_recall: 0.5 (control group fact missing from context)
Answer Relevancy
Measures whether the response actually addresses the question. This catches a different failure mode from faithfulness: a response can be entirely grounded in context and still not answer what was asked.
The RAGAS implementation uses an interesting approach: generate N synthetic questions from the response, then measure embedding similarity between those questions and the original question. If the response addresses the question, the derived questions should cluster near the original.
from ragas.metrics import answer_relevancy
# Faithful but not relevant
data = Dataset.from_dict({
"question": ["What is the refund timeline for digital products?"],
"answer": [
# Faithful to retrieved context, but about the wrong product category
"Physical products can be returned within 30 days with original packaging."
],
"contexts": [[
"Physical products can be returned within 30 days with original packaging.",
"Digital products are non-refundable after download."
]],
"ground_truth": ["Digital products are non-refundable after download."]
})
results = evaluate(data, metrics=[answer_relevancy])
# answer_relevancy: 0.31 — low despite faithful response
LLM-as-Judge: When It Works and When It Doesn’t
LLM-as-judge is increasingly used because it correlates well with human preference, especially for open-ended tasks where lexical or NLI-based metrics fail. But it’s not free of problems.
Known biases:
- Self-enhancement bias: models rate their own outputs higher than equivalent outputs from other models. Don’t use GPT-4 to judge GPT-4 outputs.
- Verbosity bias: longer, more elaborate responses are rated higher even when a shorter response is more accurate.
- Position bias (pairwise setting): in A/B comparisons, the first option gets a slight bump. Mitigate by swapping order and averaging.
- Format bias: responses with markdown formatting, headers, and bullet points tend to score higher regardless of content quality.
Mitigation strategies:
def robust_llm_judge(question: str, response: str, context: str) -> dict:
"""
More reliable LLM judging with structured output and chain-of-thought.
Uses a different model family from what generated the response.
"""
prompt = f"""You are evaluating a RAG system response.
Question: {question}
Retrieved context: {context}
Response: {response}
Evaluate on these dimensions. Think step-by-step before scoring.
1. Faithfulness (0-1): Are all claims in the response supported by the context?
Reasoning: <explain each claim>
Score: <0.0-1.0>
2. Relevancy (0-1): Does the response address what was asked?
Reasoning: <explain>
Score: <0.0-1.0>
3. Completeness (0-1): Are all aspects of the question addressed?
Reasoning: <explain>
Score: <0.0-1.0>
Return valid JSON: {{"faithfulness": X, "relevancy": X, "completeness": X, "reasoning": "..."}}"""
# Use a different model family from the one being evaluated
response = anthropic_client.messages.create(
model="claude-opus-4-7",
max_tokens=512,
messages=[{"role": "user", "content": prompt}]
)
return json.loads(response.content[0].text)
Chain-of-thought helps, but it doesn’t eliminate bias. The safest approach: use LLM-judge for a sample (5-10% of traffic in production, 100% in offline eval) and periodically audit the judge against human labels on a held-out set. If your judge and your human raters disagree on more than 15-20% of cases, the judge is miscalibrated.
Evaluation Data Construction
This is where most teams underinvest, and it’s the most common reason evaluation results don’t transfer to production.
The synthetic question trap: If you generate test questions by asking an LLM “generate questions from this document,” you’ll get questions that are easy to answer from the document. Real user queries are messier, more ambiguous, and often require reasoning across multiple chunks. Synthetic eval sets overestimate your system’s performance.
What actually works:
- Mine production logs — even before you have labels, real queries tell you what your users actually ask. Cluster by intent, then manually label a representative sample.
- Adversarial examples — include queries the system should refuse: questions outside the document scope, queries for which the answer has changed, ambiguous queries. A system that hallucinates on these is a liability.
- Multi-hop questions — questions requiring synthesis across multiple documents stress-test both retrieval recall and the generator’s ability to combine information.
- Label faithfulness directly — for a critical domain (legal, financial, medical), have domain experts annotate which claims in responses are supported vs. hallucinated. This is expensive but gives you ground truth to calibrate your automated metrics.
def build_evaluation_dataset(log_store, domain_expert=None):
"""
Example data pipeline for real-world eval set construction.
"""
# Step 1: Sample from production logs
queries = log_store.sample(
n=500,
stratify_by="intent_cluster", # ensure coverage
date_range="last_60_days" # avoid recency bias
)
# Step 2: Deduplicate near-duplicates
queries = semantic_dedup(queries, threshold=0.92)
# Step 3: Run your current system to get responses
labeled = []
for q in queries:
result = rag_system.query(q.text)
labeled.append({
"question": q.text,
"answer": result.answer,
"contexts": result.retrieved_chunks,
"intent": q.intent_cluster
})
# Step 4: If domain expert available, add faithfulness labels
if domain_expert:
labeled = domain_expert.annotate_claims(labeled)
return Dataset.from_list(labeled)
Framework Comparison: DeepEval, RAGAS, and LangSmith
| DeepEval | RAGAS | LangSmith | |
|---|---|---|---|
| Focus | General LLM testing | RAG metrics | Tracing + evaluation |
| Integration style | pytest-like | HuggingFace Datasets | LangChain-first |
| Metric computation | LLM-judge (customizable) | LLM-judge + NLI | Configurable |
| Best for | CI/CD regression testing | Offline RAG experimentation | Production tracing + sampling |
| Main limitation | LLM-judge calls add latency/cost | LLM calls, Requires HF Datasets format | LangChain coupling |
RAGAS is the easiest entry point for RAG-specific metrics. The faithfulness, context precision, and context recall implementations are solid and well-documented. The main friction is the Dataset format requirement and the fact that all metrics call an LLM internally — budget accordingly.
from ragas import evaluate
from ragas.metrics import (
faithfulness,
context_precision,
context_recall,
answer_relevancy,
)
from datasets import Dataset
# A realistic RAG eval case: financial document QA
data = Dataset.from_dict({
"question": [
"What was Q3 operating margin and how did it compare to guidance?",
"What were the primary drivers of increased SG&A in 2025?"
],
"answer": [
"Q3 operating margin was 18.2%, which came in 140bps above the guidance range of 16.5-17.0%.",
"SG&A increased primarily due to higher headcount in sales (up 23% YoY) and expanded marketing spend ahead of the product launch."
],
"contexts": [
[
"Q3 2025 operating margin: 18.2%. Full year guidance provided in August was 16.5-17.0%.",
"Revenue grew 14% YoY to $2.3B in Q3."
],
[
"SG&A increased $47M YoY, driven by 23% headcount growth in sales and $18M incremental marketing investment related to the Apex product launch."
]
],
"ground_truth": [
"18.2%, 140bps above the 16.5-17.0% guidance.",
"Higher sales headcount (23% YoY) and increased marketing spend for the Apex launch."
]
})
result = evaluate(data, metrics=[faithfulness, context_precision, context_recall, answer_relevancy])
print(result.to_pandas())
DeepEval is better suited for treating evaluation as a continuous testing concern — it integrates with pytest, supports custom metrics, and makes it natural to add LLM evaluation gates to CI/CD. The tradeoff: every metric invocation calls an LLM, so running the full suite on a large dataset is slow and costly. Structure your test pyramid: a small golden test set in CI (50-100 cases), a larger eval set run less frequently (nightly or pre-release).
import pytest
from deepeval import assert_test
from deepeval.test_case import LLMTestCase
from deepeval.metrics import FaithfulnessMetric, ContextualRecallMetric
# Golden test cases — curated, high-confidence ground truth
GOLDEN_CASES = [
{
"input": "What was the Q3 operating margin?",
"expected_output": "18.2%",
"context": ["Q3 2025 operating margin: 18.2%."],
},
# ... more carefully curated cases
]
@pytest.mark.parametrize("case", GOLDEN_CASES)
def test_rag_golden(case):
result = rag_system.query(case["input"])
test_case = LLMTestCase(
input=case["input"],
actual_output=result.answer,
expected_output=case["expected_output"],
retrieval_context=result.retrieved_chunks,
)
assert_test(test_case, [
FaithfulnessMetric(threshold=0.85),
ContextualRecallMetric(threshold=0.8),
])
LangSmith is primarily an observability platform with evaluation capabilities bolted on. If you’re not using LangChain, the integration is more awkward. Its strength is production tracing — you can log every retrieval and generation step, then run evaluators asynchronously over the logged traces. This makes it easy to measure quality on real traffic without adding latency to the critical path.
RAG Evaluation vs. Production Observability
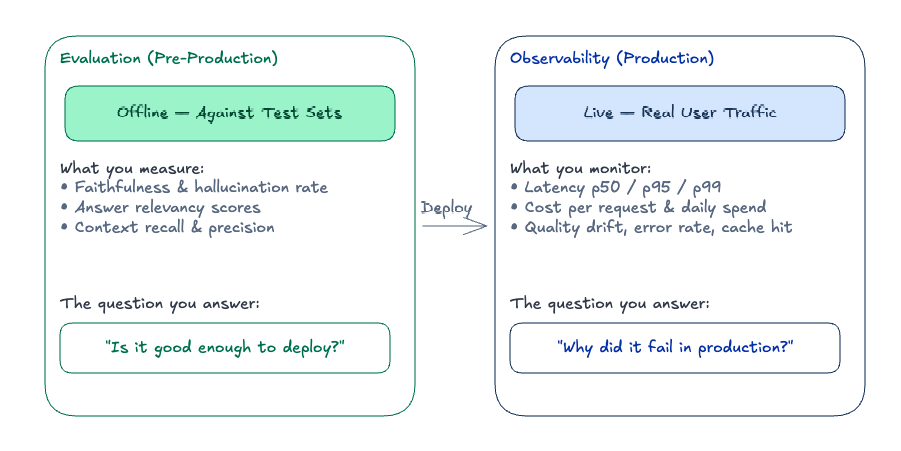
These two things solve different problems and require different infrastructure.
Evaluation is offline: you run your system against a fixed dataset, compute metrics, and use the results to decide whether to deploy. It’s where you catch regressions before they hit users.
Observability is online: you instrument your production system, sample traffic, run lightweight quality checks asynchronously, and alert when metrics degrade. LLMs fail silently — a hallucinated but plausible answer doesn’t throw an exception — so you need this layer even when evaluation looks good in staging.
The critical point: your evaluation distribution will drift from your production distribution. Users ask questions you didn’t anticipate. Documents in your corpus change. Models get updated. Build a pipeline to continuously harvest production queries back into your eval set.
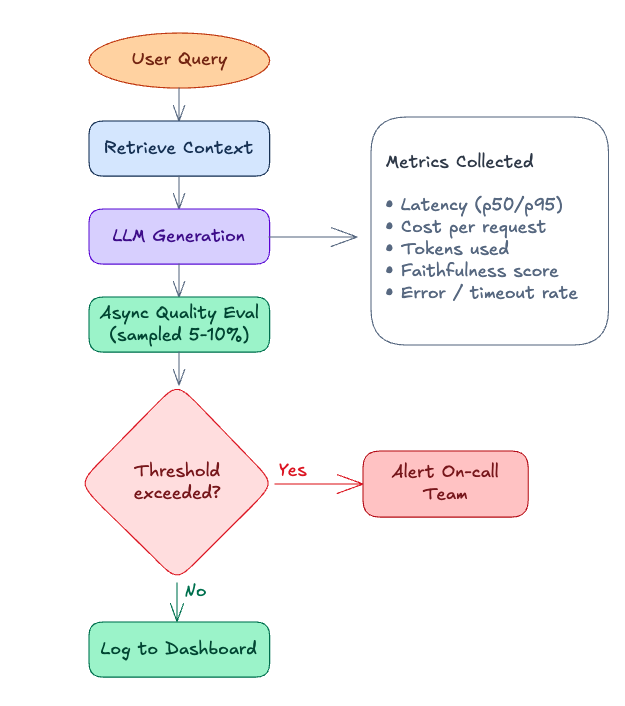
import asyncio
import random
from dataclasses import dataclass
@dataclass
class RAGResponse:
answer: str
retrieved_chunks: list[str]
latency_ms: float
input_tokens: int
output_tokens: int
class InstrumentedRAGSystem:
"""
Production RAG with async quality sampling.
Evaluation runs off the critical path — does not add latency to user requests.
"""
EVAL_SAMPLE_RATE = 0.05 # evaluate 5% of traffic
def __init__(self, retriever, generator, tracer, evaluator):
self.retriever = retriever
self.generator = generator
self.tracer = tracer
self.evaluator = evaluator
async def query(self, question: str, user_id: str) -> RAGResponse:
with self.tracer.span("rag_query", {"user_id": user_id}) as span:
import time
t0 = time.monotonic()
chunks = await self.retriever.retrieve(question, top_k=5)
span.set("retrieval.chunk_count", len(chunks))
response = await self.generator.generate(question, chunks)
latency_ms = (time.monotonic() - t0) * 1000
span.set("generation.input_tokens", response.input_tokens)
span.set("generation.output_tokens", response.output_tokens)
span.set("latency_ms", latency_ms)
# Fire-and-forget quality evaluation — does not block response
if random.random() < self.EVAL_SAMPLE_RATE:
asyncio.create_task(
self._evaluate_async(question, response.answer, chunks, span.trace_id)
)
return RAGResponse(
answer=response.answer,
retrieved_chunks=chunks,
latency_ms=latency_ms,
input_tokens=response.input_tokens,
output_tokens=response.output_tokens,
)
async def _evaluate_async(self, question, answer, chunks, trace_id):
scores = await self.evaluator.score(question, answer, chunks)
self.tracer.attach_scores(trace_id, scores)
if scores["faithfulness"] < 0.7:
self.tracer.flag_for_review(trace_id, reason="low_faithfulness")
What to alert on: not every metric deserves an immediate page. A useful mental model:
| Metric | Alert level | Threshold example |
|---|---|---|
| Faithfulness p25 (rolling 1h) | Page | < 0.65 |
| Context recall p50 | Slack | < 0.75 |
| Latency p95 | Page | > 2000ms |
| Error rate | Page | > 1% |
| Cost per request (rolling 24h) | Slack | > 1.5x baseline |
Use a rolling window rather than point-in-time metrics. A single bad batch response or a 30-second spike shouldn’t page anyone.
Common RAG Evaluation Pitfalls (and How to Avoid Them)
Evaluating retrieval and generation together obscures where failures originate. Compute context recall and context precision separately before computing faithfulness. If context recall is low, fix the retriever — prompt engineering won’t help.
Automated metrics are only as good as your eval set. If your eval set is easy or synthetic, you’ll have high automated scores and poor production quality. Set aside budget for human annotation on a representative production sample, especially for the cases where automated metrics score highest (to catch false positives in your evaluator).
LLM-as-judge is biased and drifts. The same judge model will score the same response differently across versions. Re-calibrate your judge against human labels every time you change either the judge model or the system under test. Don’t use a model to evaluate its own outputs.
Sampling rate for production evaluation matters. 5% is often cited but the right rate depends on query volume and variance. At low volume (< 1000 queries/day), evaluate more aggressively (20-30%) to get statistically stable estimates. At high volume, 1-2% may be enough. Use stratified sampling by intent cluster — rare but high-stakes query types need overrepresentation.
Faithfulness doesn’t catch all hallucinations. A model can be “faithful” to retrieved context that is itself outdated or wrong. Faithfulness measures consistency with retrieved chunks, not factual accuracy. For domains where the ground truth evolves (financial data, medical literature, legal regulations), you need a separate accuracy check against authoritative sources.
Summary: Building a Robust RAG Evaluation Pipeline
RAG evaluation is a measurement system, not a single score. The three layers most production teams converge on:
- Offline eval (pre-deploy): Run RAGAS metrics — faithfulness, context precision, context recall, answer relevancy — against a curated eval set. Catches regressions before they reach users.
- CI/CD regression gates: Use DeepEval with pytest. A small golden test set (50–100 well-annotated cases) with hard thresholds. Fails the build if faithfulness drops below your baseline.
- Production monitoring: Sample 5–20% of live traffic (depending on volume), run async LLM-as-judge scoring off the critical path, and alert on rolling metric windows — not point-in-time spikes.
If you’re starting from scratch: RAGAS first to understand your baseline → DeepEval once you have a stable eval set → production observability when you’re shipping to real users.
Resources
- RAGAS paper — the metric definitions and methodology behind the Ragas library
- Judging the Judges — systematic analysis of LLM-as-judge biases
- ARES: An Automated Evaluation Framework for RAG — alternative approach using classifier-based evaluation
- Hallucination Leaderboard — cross-model hallucination comparison on a standardized task