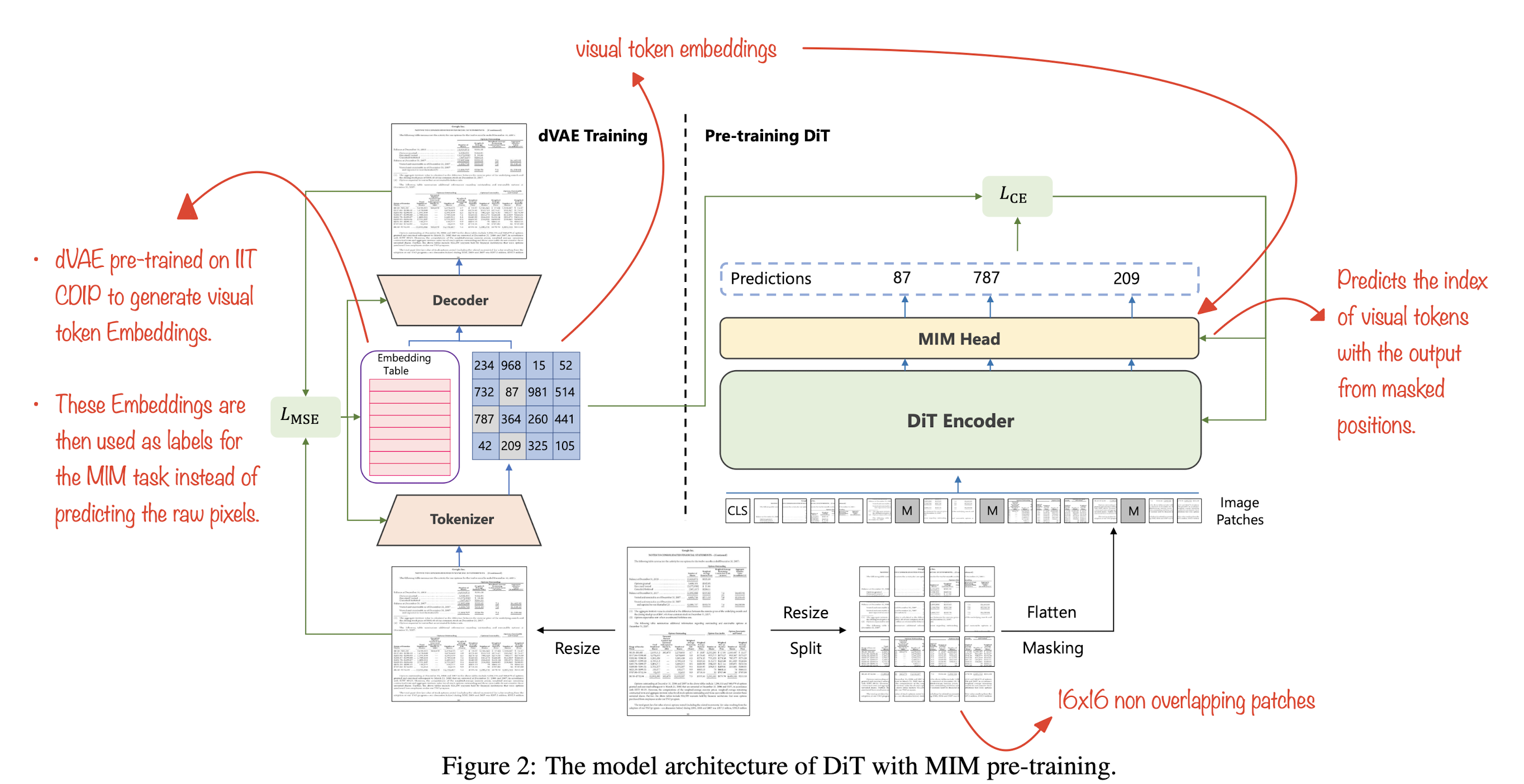
DIT: SELF-SUPERVISED PRE-TRAINING FOR DOCUMENT IMAGE TRANSFORMER
DocumentAI with Images has a new leader in town and its DiT! A yet another stellar paper from the folks at Microsoft advancing the field of DocumentAI. This new paper essentially draws inspiration from various papers to come up with a clean end-to-end pre-trained network for various image tasks like document image classification, document layout analysis, table detection, etc. This also lays a foundation for all the upcoming multimodal networks for document understanding and plays an important role in the upcoming LayoutLMv3. Read along to explore this easy-to-read paper which potentially generates a lot of impact in the field.
Please feel free to read along with the paper with my notes and highlights.
| Color | Meaning |
|---|---|
| Green | Topics about the current paper |
| Yellow | Topics about other relevant references |
| Blue | Implementation details/ maths/experiments |
| Red | Text including my thoughts, questions, and understandings |