
DiT Annotated Paper
DIT: SELF-SUPERVISED PRE-TRAINING FOR DOCUMENT IMAGE TRANSFORMER
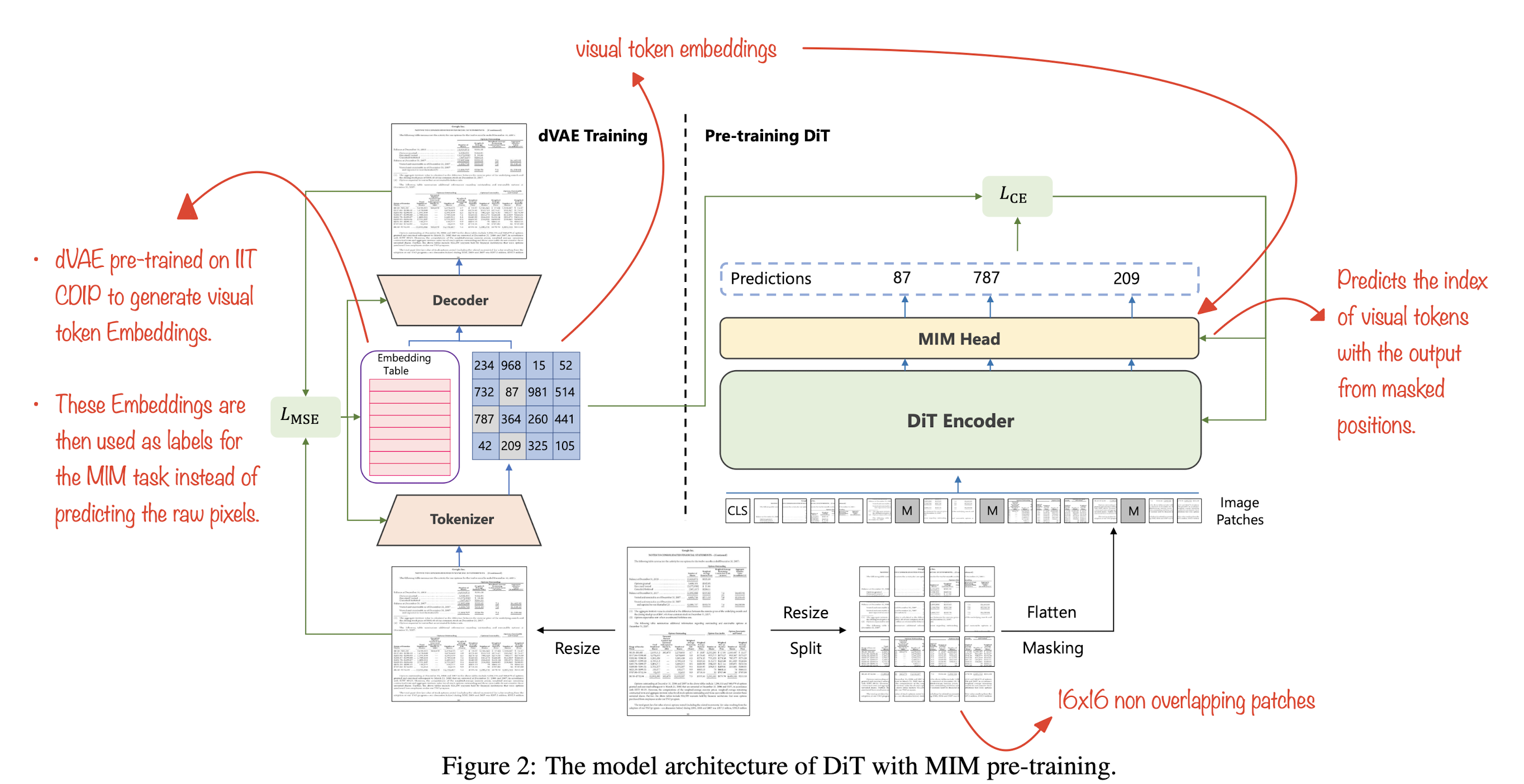
DocumentAI with Images has a new leader in town and its DiT! A yet another stellar paper from the folks at Microsoft advancing the field of DocumentAI. This new paper essentially draws inspiration from various papers to come up with a clean end-to-end pre-trained network for various image tasks like document image classification, document layout analysis, table detection, etc. This also lays a foundation for all the upcoming multimodal networks for document understanding and plays an important role in the upcoming LayoutLMv3. Read along to explore this easy-to-read paper which potentially generates a lot of impact in the field.
Please feel free to read along with the paper with my notes and highlights.
| Color | Meaning |
|---|---|
| Green | Topics about the current paper |
| Yellow | Topics about other relevant references |
| Blue | Implementation details/ maths/experiments |
| Red | Text including my thoughts, questions, and understandings |
Follow me on Github and star this repo for regular updates. GitHub
Also, Follow me on Twitter.
PS: For now, the PDF Above does not render properly on mobile devices, so please download the pdf from the above button or get it from my Github
CITATION
@misc{https://doi.org/10.48550/arxiv.2203.02378,
doi = {10.48550/ARXIV.2203.02378},
url = {https://arxiv.org/abs/2203.02378},
author = {Li, Junlong and Xu, Yiheng and Lv, Tengchao and Cui, Lei and Zhang, Cha and Wei, Furu},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {DiT: Self-supervised Pre-training for Document Image Transformer},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}